-min-min.png)
Forget everything you thought you knew about AI! Literally!
Yes, we are not lying because a new era has already begun. A technology is emerging that doesn’t just compute… it perceives. It listens, observes, reads, and interprets the world with a blend of senses much closer to our own. It’s the age of multimodal AI, where intelligence is no longer limited to a single stream of data, but fuelled by the combined power of text, images, audio, and video.
This multisensory capability is reshaping how machines understand human intent and context. The shift from traditional, single-mode AI to multimodal systems marks a pivotal moment for the enterprise landscape where interactions become more intuitive, decisions more informed, and experiences more immersive.
However, in parallel, Generative AI (GenAI) continues to unlock new thresholds of innovation like accelerating enterprise reinvention, powering AI-driven operations, and enabling experiences that blur the boundaries between digital and physical worlds.
But…but…but, at the center of this evolution stands the Multimodal AI model, which is the clearest evidence of how far GenAI has come. Designed to interpret inputs across multiple formats and deliver insights in real time, this technology acts as the eyes, ears, and cognitive engine behind next-generation AI systems.
Why is that so?
No wonder C-suite leaders are calling multimodal AI the next big inflection point. Its impact spans everything from conversational intelligence and data analytics to autonomous systems and robotics. And the momentum is undeniable because the global multimodal AI market, valued at USD 1.73 billion in 2024, is expected to surge at a 35.8% CAGR from 2024 and will reach USD 10.89 billion by 2030, signaling a rapid shift toward multisensory AI adoption across industries.
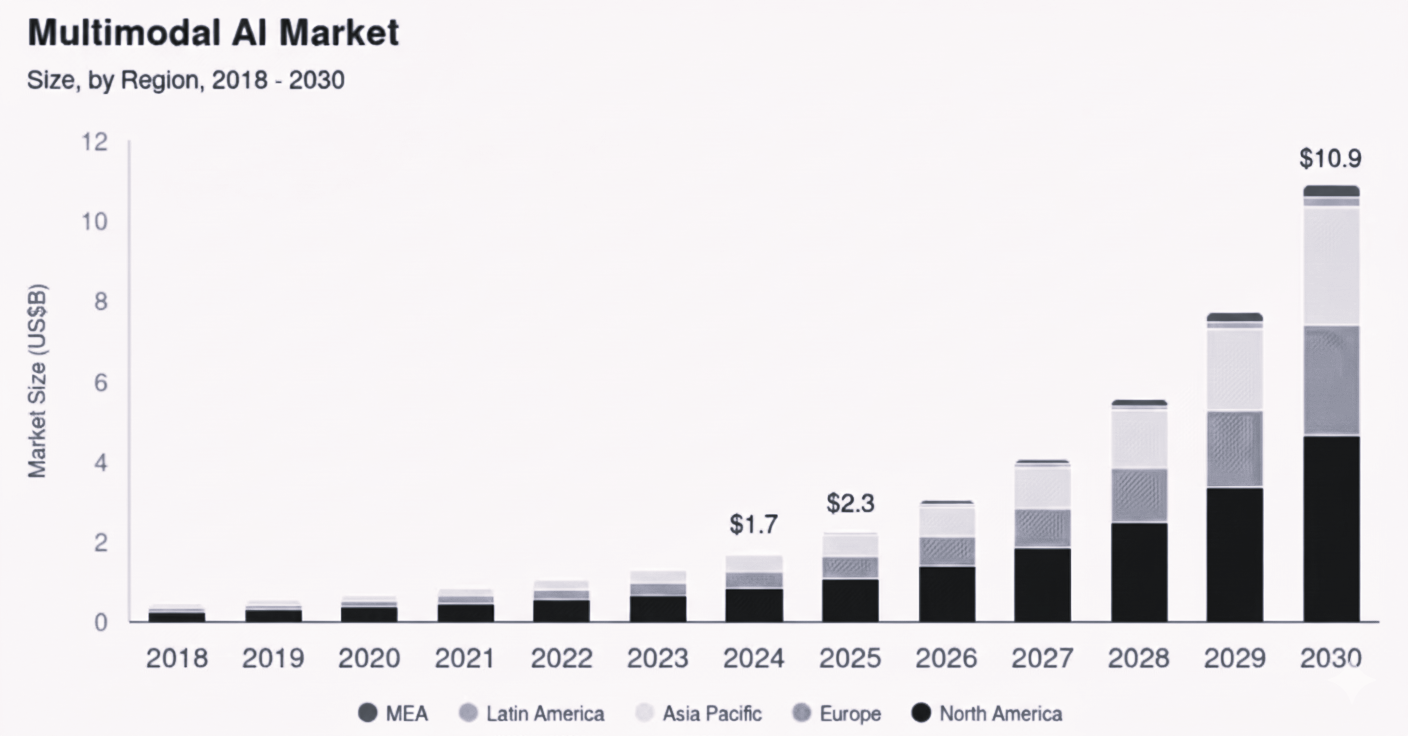
Analysts echo this trajectory. Gartner predicts that multimodal AI will have a “transformational impact” on enterprises, which will redefine human-machine interaction and expand the boundaries of enterprise intelligence as we move into 2026 and beyond.
Multimodal AI represents the next evolution of artificial intelligence that mirrors the way humans naturally perceive and interpret the world. Instead of relying on a single stream of data, these systems can understand multiple modalities at once, including text, images, audio, and video.
This ability to synthesize diverse inputs allows the model to build a far more holistic and contextual understanding. Traditional AI might read text or recognize an image, but multimodal AI can combine both to derive deeper meaning. For example, the system can look at a picture of a dog, interpret a question asking for its breed, and respond accurately by correlating visual and textual cues.
This convergence of sensory data is foundational to unlocking advanced real-world applications. Autonomous vehicles integrate camera feeds, radar, and lidar in real time to navigate safely. Virtual assistants can understand a spoken command while simultaneously interpreting what the camera sees. In short, multimodal AI is enabling a new generation of systems that reason more like humans and act with greater precision.
At its core, multimodal AI operates by bringing together insights from different data streams to form a unified, contextually enriched understanding. The process typically unfolds in three interconnected stages…
.png)
The journey begins with each type of input being processed through a specialized model.
Regardless of the modality, each input is translated into a common machine-understandable format like vector embeddings. Whether it’s a sentence, a pixel pattern, or a sound wave, all data becomes numerical representations that can be aligned, compared, and combined. This conversion lays the groundwork for deeper cross-modal understanding.
Once each input is converted, the system moves to the most critical phase, and that is fusion. During this stage, neural networks learn how different modalities relate to each other. For example, the model internalizes that the phrase “golden retriever” corresponds to a particular visual pattern or that an audio clip of barking may correlate with the image of a dog.
This fusion layer allows the AI to build richer semantic connections, enabling a more nuanced interpretation of complex situations. It’s this cross-modal reasoning that gives multimodal systems their unique advantage over traditional single-modality approaches.
Finally, the integrated insights are used to generate a unified, context-aware response. Depending on the need, the output may include:
By drawing from multiple modalities simultaneously, multimodal AI overcomes the narrow perspectives of traditional models and delivers more accurate, relevant, and human-like outcomes.
Traditional AI systems, often referred to as unimodal AI, are designed to work with a single type of data. They excel in narrow, well-defined tasks such as text classification, image recognition, or speech-to-text conversion. However, they operate in isolation: an NLP model can understand sentences but cannot interpret images; a vision model can detect objects but cannot understand spoken instructions. This siloed approach limits their ability to grasp real-world complexity, where information almost always appears in multiple forms.
Multimodal AI, on the other hand, breaks these boundaries. It processes and interprets multiple data modalities at the same time, including text, images, creating videos, audio, and more, and blends them to form a deeper, more contextual understanding. Think of it as moving from a single sense to a full sensory suite. This allows the AI to recognize patterns that would be invisible in unimodal systems and generate richer, human-like responses.
Where unimodal AI provides accuracy within its specific domain, multimodal AI provides intelligence across domains. This shift fundamentally changes how systems understand interactions, reason about complex environments, and support decision-making.
From autonomous vehicles and diagnostic imaging to conversational assistants that see and hear simultaneously, multimodal AI represents a major leap forward by enabling applications that demand a comprehensive, multisensory perspective rather than a narrow viewpoint.
Multimodal AI is a practical enabler that is already reshaping industries, customer experiences, and enterprise operations. By combining multiple types of data, such as text, visuals, audio, and sensor inputs, multimodal systems provide a more complete and human-like understanding of situations. This deeper contextual intelligence unlocks powerful applications across real-world environments.
Below are some of the most impactful and relatable use cases where multimodal AI is making a measurable difference today.
Traditional virtual assistants only understand text or voice. Multimodal AI changes this entirely.
Imagine an assistant that can:
Whether it’s troubleshooting a device during a video call or helping visually impaired users understand their surroundings, multimodal assistants offer a more natural, intuitive, and context-aware experience.
Healthcare generates complex data like scans, lab reports, patient histories, and real-time sensor information. Multimodal AI brings these scattered data points together.
It powers:
This holistic view improves accuracy, reduces clinician workload, and increases the speed of medical decision-making.
Self-driving systems rely on real-time interpretation of multiple sensory streams:
Multimodal AI merges these modalities to understand the environment, detect obstacles, read road signs, and predict human behavior more reliably. This sensory fusion is the backbone of safer autonomous navigation and next-gen mobility systems.
From marketing teams to entertainment studios, multimodal AI is transforming creative workflows.
It enables:
By blending creativity with contextual insight, multimodal AI becomes a true co-pilot for designers, writers, and creators.
Retailers now use multimodal AI to deliver experiences that feel almost concierge-level.
Examples include:
It combines customer intent, visual cues, and shopping patterns to provide smarter and more relevant suggestions.
.png)
Security systems traditionally analyzed video alone. Multimodal AI moves beyond that.
It integrates:
This allows enterprises to detect anomalies with far greater precision, whether it's unusual movement patterns, voice mismatches, or inconsistent visual cues, providing a stronger, layered approach to safety. Additionally, an intelligent video management system unifies everything and enables security teams to surface critical incidents in seconds rather than sifting through hours of footage.
Multimodal AI enriches learning by adapting to how students naturally absorb information.
Examples include:
This creates a more personalized and engaging learning environment.
In factories or field operations, robots must understand instructions and interpret their environment dynamically.
Multimodal AI powers robots that can:
This makes industrial automation more adaptable, responsive, and safer.
The future of customer support is multimodal.
Service bots can now:
This leads to faster resolutions, lower manual workload, and more empathetic interactions.
Multimodal AI is bridging the gap between human perception and machine intelligence. By integrating data the same way humans use multiple senses, it is enabling next-generation solutions across healthcare, mobility, retail, security, and enterprise operations.
Multimodal AI is already woven into the routines of our daily lives. From the apps we use to the devices we depend on, multimodal intelligence quietly enhances convenience, personalizes experiences, and makes technology feel more human.
Here are some real, relatable examples of where you encounter multimodal AI every single day.
When you say, “What’s this?” while pointing your camera at an object, your phone analyzes both:
This combination allows your assistant to identify objects, translate text from images, or guide you through complex tasks. It’s multimodal AI turning your phone into a mini problem-solver.
Modern phones and smart devices often pair face recognition with speech detection for verification. For instance…
This blend of biometrics and commands is classic multimodal AI at work.
Platforms like Instagram, Snapchat, and TikTok use multimodal AI when they:
These features work because the AI understands multiple signals simultaneously.
Apps such as Google Lens or translation tools combine:
This allows you to take a photo of a sign written in another language and instantly see the translated version. A perfect example of multimodal understanding in everyday travel.
Apps like Google Maps or systems in modern cars merge:
This multimodal blend helps the system provide lane guidance, detect obstacles, and give spoken directions, all in real time.
.png)
When you upload a picture and search “Find similar products,” multimodal AI combines:
This experience is powered by visual recognition + language understanding working together.
These devices use:
You can ask for a recipe, show your fridge to the camera, and get suggestions, all through multimodal processing.
During meetings, platforms like Zoom or Teams use multimodal AI to:
A mix of audio + facial cues + text processing enhances communication.
Smart watches and fitness platforms combine:
This allows them to track exercises, detect posture, and guide you with voice or screen prompts.
Every time you upload a picture of a damaged product or send a voice note to a support bot, multimodal AI is processing:
This helps provide more accurate and empathetic assistance.
Multimodal AI is already everywhere and fueling smarter devices, intuitive apps, and more immersive experiences. From unlocking your phone to browsing social media, using GPS, or shopping online, you’re interacting with multimodal systems more often than you realize.
Multimodal AI is rapidly moving from theoretical innovation to mainstream adoption. Leading global brands and forward-thinking Indian enterprises have already integrated multimodal intelligence into their products, platforms, and customer ecosystems. These companies are combining text, images, video, audio, and sensor data to deliver richer experiences and unlock deeper insights.
Below are some prominent organizations that demonstrate the breadth of multimodal AI applications in the real world.
Netflix uses multimodal AI to create a highly personalized content discovery experience. The platform blends viewing history, thumbnail interactions, scene visuals, audio sentiment, and text metadata to recommend the most relevant titles for each user.
Its systems understand not only what users watch but also how they respond to specific visuals, sound patterns, and story elements. This multimodal approach strengthens engagement, reduces churn, and improves overall content performance across global markets.
Snapchat’s AR experiences are powered by multimodal AI that interprets facial landmarks, movements, voice signals, environmental objects, and on-screen text at the same time. This intelligence enables real-time filters, interactive lenses, gesture-based features, and voice-activated effects.
Its ability to process multiple modalities simultaneously makes Snapchat one of the most advanced consumer platforms for immersive AI-driven interactions.
Meta applies multimodal AI across its family of apps and in its work on future immersive environments. The company’s systems learn from speech, images, text, and video to power features like auto-captions, real-time translation, content safety, creator tools, and personalized recommendations.
Meta’s foundational multimodal models are also shaping the building blocks of metaverse experiences, where visual, auditory, and behavioral inputs come together seamlessly.
Jio employs multimodal AI to support high-volume customer operations and enhance digital services. Its assistants combine voice commands, text-based queries, and behavioral patterns to deliver accurate, vernacular-friendly support.
Multimodal systems also help Jio analyze device diagnostics, sentiment patterns, and user interactions to improve service quality and product recommendations at a massive scale.
Antino is actively advancing multimodal AI capabilities across its engineering and product innovation initiatives. The company integrates text, images, audio inputs, and behavioral data to build intelligent digital experiences for clients in sectors like healthcare, fintech, mobility, and consumer apps.
Antino’s teams apply multimodal intelligence in areas such as customer journey automation, image-based verification, video analytics, voice-assisted workflows, real-time data interpretation, and personalized content generation. By combining multimodal models with enterprise-grade engineering, Antino helps businesses adopt AI ecosystems that are scalable, context-aware, and aligned with real-world user behavior.
From consumer technology leaders like Netflix and Snapchat to enterprise innovators like Reliance Jio and Antino, multimodal AI is becoming a competitive differentiator across industries. These companies, including us, are proving that when systems can listen, see, read, and interpret simultaneously, the quality of insights, experiences, and decisions improves dramatically.
Implementing multimodal AI is not just a technology upgrade. It is a strategic shift that enables organizations to deliver richer experiences, automate complex processes, and unlock deeper insights from diverse data sources. Companies that adopt multimodal AI thoughtfully can transform customer interactions, enhance operational intelligence, and differentiate themselves in competitive markets.
Below are the key steps organizations can follow to successfully introduce multimodal AI into their products and services.
The first step is understanding where multimodal intelligence can make the greatest impact. Companies should map their customer journeys, operational workflows, and data touchpoints to identify areas where multiple data streams already exist.
Examples include:
Selecting use cases that solve real business problems helps demonstrate early value and accelerates adoption.
Multimodal AI relies on high-quality, diverse data. Organizations need to bring together text, images, audio, video, sensor signals, or transactional logs into a unified data strategy.
Key steps involve:
This foundational data work is critical for building models that are accurate, context-aware, and scalable.
Companies can select from a growing ecosystem of multimodal AI models, including open-source, commercial, and domain-specific options. Decisions should align with business needs and technical maturity.
Considerations include:
The right model choice balances performance, cost efficiency, and long-term scalability.
Once a model is selected, it must be embedded into real business processes. This requires seamless integration with applications, user interfaces, and backend systems.
Implementation typically involves:
For customer-facing products, thoughtful UX design is essential to ensure users intuitively understand how to interact with multimodal features.
.png)
A controlled pilot helps validate the multimodal solution before full-scale rollout. During pilots, companies focus on:
Based on insights, the system is refined, retrained, or optimized to meet performance standards.
Multimodal models handle large volumes of sensitive data. Companies must embed security, fairness, and compliance into both design and deployment.
Key considerations include:
Responsible AI practices help build trust and support long-term adoption.
Once validated, companies can scale multimodal AI across product lines and departments. A continuous improvement loop ensures models stay accurate as new data and behaviors emerge.
Scaling involves:
Organizations that treat multimodal AI as an evolving capability, rather than a one-time implementation, realize the greatest benefits.
Implementing multimodal AI requires a balance of strategic planning, data readiness, technical integration, and responsible governance. Companies that invest early and thoughtfully can unlock powerful advantages, including more intuitive user experiences, smarter decision-making, and streamlined operations. As multimodal AI becomes the new frontier of enterprise intelligence, organizations that adopt it now will set the benchmark for innovation in the years ahead.
Absolutely. As multimodal AI becomes more embedded in products and operations, it introduces a new layer of complexity that goes far beyond traditional AI risk considerations. Because these systems process combined inputs like text, images, voice, documents, and user behavior data, the potential exposure, if not managed responsibly, increases significantly. Organisations must therefore treat security, privacy, and bias not as afterthoughts but as foundational design principles.
Multimodal AI systems constantly ingest and interpret rich, high-volume data from different sources. This creates a broader “attack surface” for cyber threats.
Examples include:
To mitigate this, enterprises should:
Multimodal AI cannot be treated like a standalone text model. Every new modality introduces a new avenue of vulnerability if left unmanaged.
Traditional AI might use text or numeric data, but multimodal systems often process highly sensitive elements like faces, voices, images, behavioral cues, or location metadata.
This increases the risk of:
To ensure responsible deployment, organizations should:
Multimodal AI must be implemented with the same level of caution as biometric systems, because the nature of the data is equally sensitive.
In unimodal models, you can check a dataset and identify textual or numerical biases. But multimodal AI learns from a mix of visual cues, audio tones, languages, gestures, and contextual information. Bias can creep in silently and manifest in ways that are difficult to trace.
Examples include:
To mitigate multimodal bias, companies should:
Bias in multimodal AI is not a technical issue alone. It is a socio-technical challenge requiring both engineering and ethical governance.
Companies should absolutely be concerned about security, privacy, and bias when deploying multimodal AI. These systems are powerful and transformative, but they also demand stronger guardrails, governance frameworks, and continuous monitoring. When designed responsibly, multimodal AI becomes a strategic advantage. However, when deployed carelessly, it becomes a high-risk asset that can damage trust, compliance posture, and brand equity.
Antino is a leading AI development solutions company that helps businesses move from experimentation to real, scalable impact with multimodal AI. Our engineering teams specialise in building systems that combine text, vision, speech, sensors, and structured data into one unified intelligence layer. Whether you want to enhance customer experience, automate complex workflows, or build AI-native products, we bring deep expertise in model design, data pipelines, cloud architecture, and integration with your existing systems. From strategy to deployment, we ensure your multimodal capabilities are reliable, secure, and tuned for real-world performance.
What truly differentiates Antino is our execution-focused approach. We work closely with your teams to identify high-impact use cases, build custom models or integrate enterprise-grade APIs, and deliver production-ready solutions with measurable ROI. With robust governance practices, strong emphasis on privacy and security, and continuous optimisation frameworks, we help you implement multimodal AI responsibly and at scale. If you’re looking to transform your product or operations with next-generation AI, Antino is your partner in making it happen.









%20(1).png)












