Every organization today is racing to embed AI into its core, yet the real question isn’t which model to choose, but how to build an AI capability that truly aligns with your business goals.
Should you invest months in training a proprietary model to gain full control and differentiation? Or would adapting a pre-trained model strike a better balance between performance and time-to-market? Perhaps the fastest route lies in leveraging approaches like Retrieval-Augmented Generation (RAG), where contextual intelligence outperforms brute computational power.
The choices are complex, and the implications are significant. A recent global survey shows that while 70% of enterprises have piloted AI projects, fewer than 20% have achieved measurable ROI. Why? Because most decisions begin with technology selection, not strategic architecture.
This article breaks down the three most common build approaches, including training from scratch, fine-tuning existing models, and RAG-based implementations, analyzing how each impacts cost, scalability, governance, and long-term competitiveness.
By the end, you’ll have a practical framework to decide not just what to build, but how to build it right, ensuring your AI investments translate into real, sustainable business advantage.
Once leaders decide to build, the next strategic crossroad emerges- how much customization is truly necessary?
It’s tempting to believe that tailoring every layer of an AI system to your organization’s unique data and workflows will automatically yield better results. Yet, as many enterprises are discovering, customization can just as easily become a double-edged sword, while enhancing precision on one hand, and inflating costs and complexity on the other.
The core dilemma lies in balancing control versus efficiency. Building a fully customized model may offer unparalleled alignment with your proprietary data and business logic, but it demands vast compute resources, specialized talent, and continuous retraining. Meanwhile, lightly fine-tuned or modular approaches can deliver faster deployment and lower operational overhead, albeit with reduced interpretability and adaptability over time.
Executives are increasingly asking:
According to recent industry findings, over 60% of enterprises that built custom AI solutions exceeded their projected budgets by 30-50%, largely due to underestimated integration and retraining costs. The lesson is clear: customization must be deliberate, not default.
In the following sections, we’ll explore three distinct paths, including building from scratch, fine-tuning existing models, and adopting retrieval-augmented frameworks (RAG), and unpack how leading organizations are choosing their routes based on business objectives, data maturity, and long-term scalability, and the role of AI orchestration platforms in managing these evolving architectures.
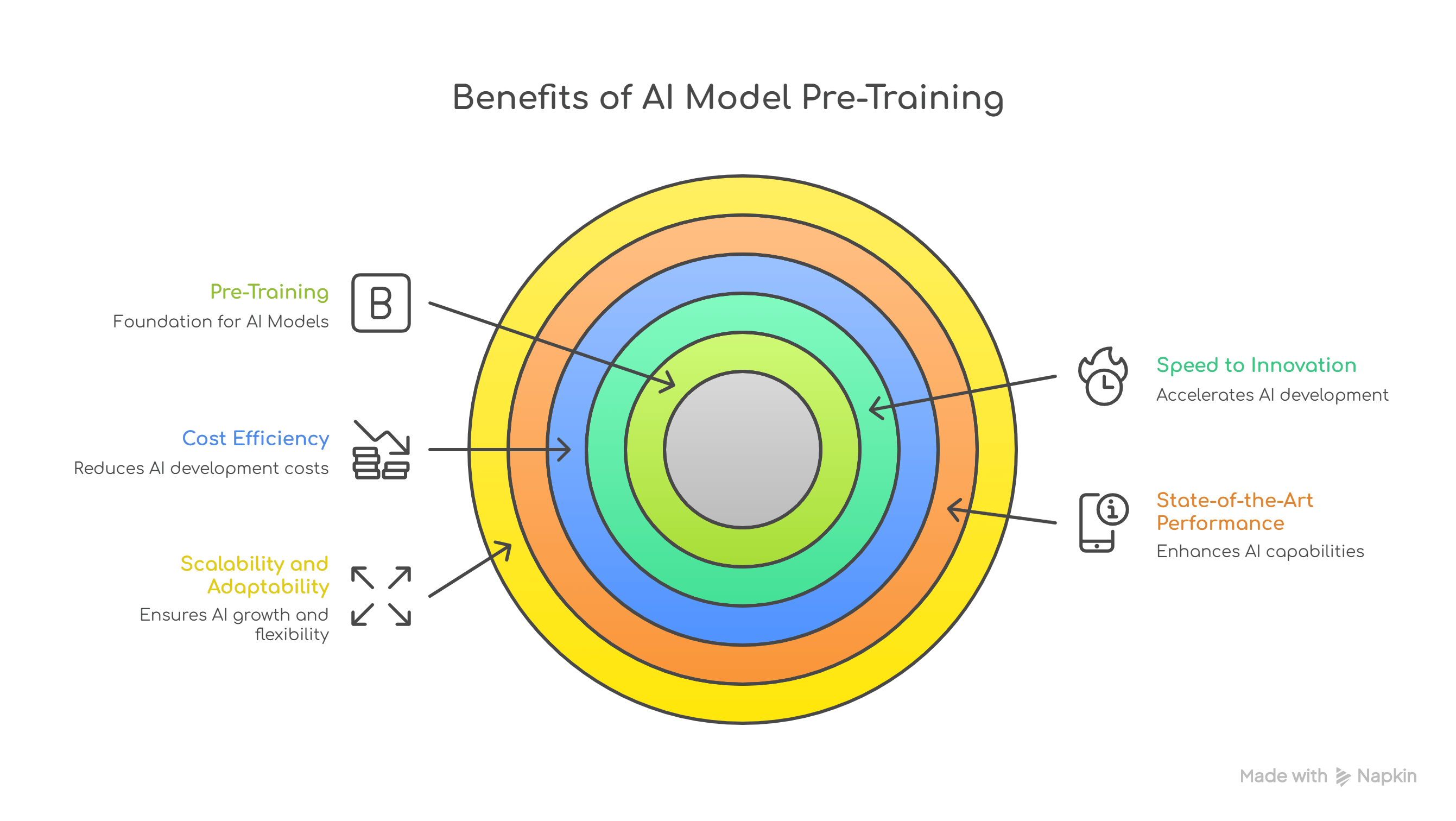
Before any AI model can analyze data, answer questions, or make predictions, it must first learn to understand the world. That learning begins with pre-training, the foundational phase that transforms raw algorithms into intelligent systems capable of processing human-like information.
In essence, pre-training is the process of teaching a model how to think, before teaching it what to think about. It involves exposing neural networks to vast, heterogeneous datasets, everything from books and websites to code repositories and technical documentation. This enables the model to internalize grammar, logic, context, and even abstract relationships between ideas. The result is a general-purpose intelligence layer that can later be refined to specific domains or business functions.
But the scale of pre-training is enormous. The world’s largest foundation models, such as GPT-4, Gemini, and Claude, have been trained on trillions of data tokens and require hundreds of petaflop-days of computation. According to estimates by Epoch AI, the average cost of training a frontier model has surged by nearly 400x since 2018, now often exceeding $100 million per model. The energy consumption and specialized hardware demands make pre-training one of the most resource-intensive stages of AI development.
For most enterprises, this raises a critical question: Is it worth building such a foundation internally?
While training from scratch offers full control, most organizations gain far greater value by adopting pre-trained foundation models as a base. These models deliver:
As Radhakanth Kodukula, Co-founder & CTO at Antino, notes:
“Pre-training gives you the brain, not the behavior. The intelligence is there, but it’s raw because it learns the world, not your world. The real innovation begins when you start shaping that intelligence around your business context.”
This observation captures the strategic essence of pre-training; it builds the capacity for intelligence, but it doesn’t yet encode your company’s competence or competitive edge. That comes later through domain-specific tuning, contextual alignment, and governance.
In fact, research by McKinsey shows that nearly 75% of enterprises adopting foundation models report faster AI integration and reduced development costs by up to 60% compared to those attempting custom builds from scratch. However, the same study warns that without careful data alignment and fine-tuning, pre-trained models can introduce biases and inaccuracies that dilute enterprise value.
For C-suite leaders, the takeaway is strategic clarity:
The true differentiator isn’t who owns the biggest model, it’s who best aligns a pre-trained foundation with their organizational DNA.
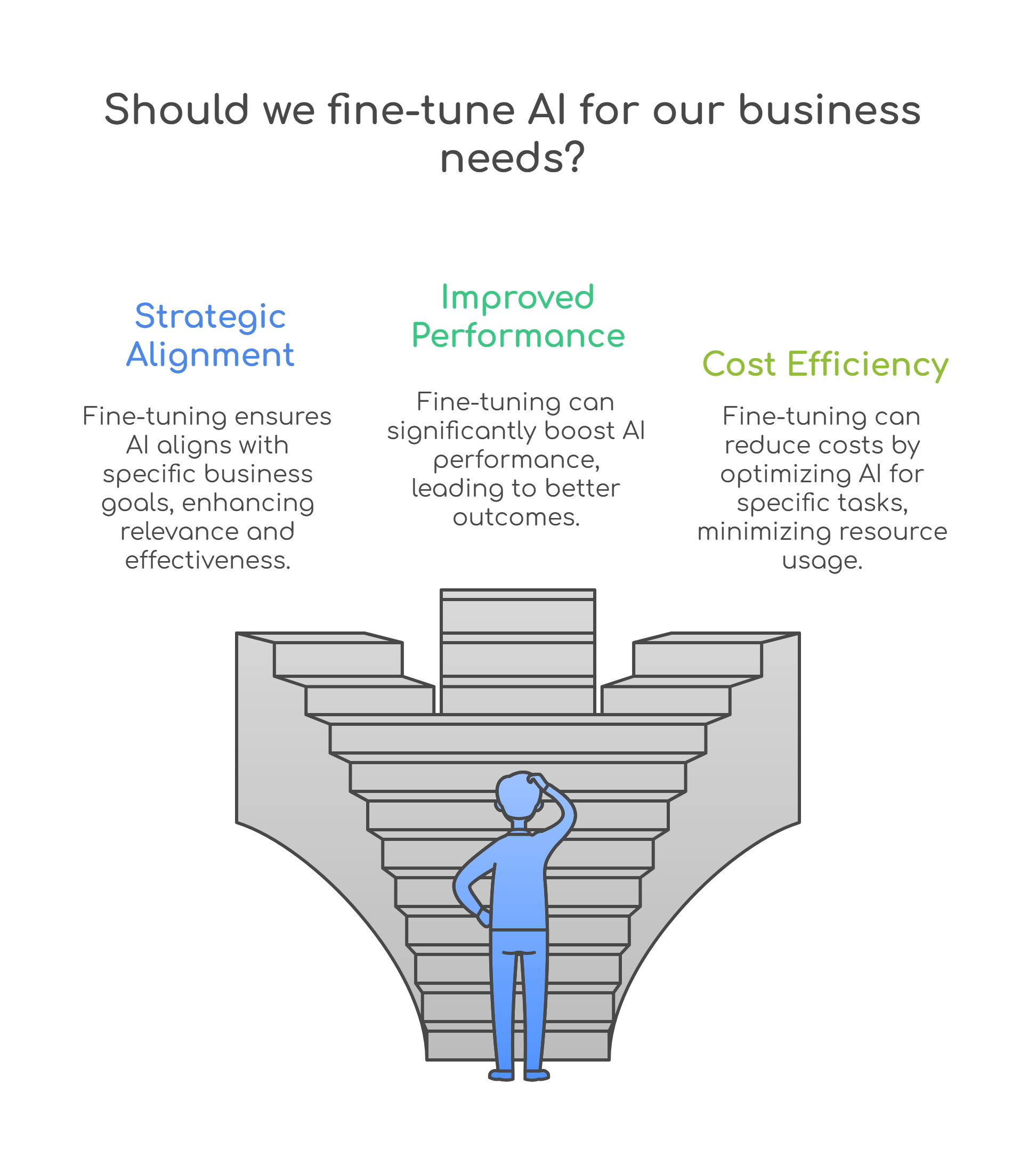
If pre-training gives AI its foundation, fine-tuning gives it purpose. It’s where a generalist model evolves into a domain expert by adapting its vast, generalized knowledge to the specific language, logic, and nuances of your business.
Fine-tuning is, in many ways, the sweet spot between building from scratch and using off-the-shelf intelligence. It doesn’t demand the massive compute and data investments of pre-training, yet it allows organizations to achieve meaningful differentiation by aligning AI behavior with proprietary data and goals.
At its core, fine-tuning involves retraining portions of a pre-trained model using your own curated datasets, be it customer support transcripts, medical records, financial transactions, or internal documentation. This process helps the model understand your tone, industry-specific terminology, compliance requirements, and even decision-making frameworks unique to your organization.
For most enterprises, fine-tuning represents the most practical route to AI maturity. It enables leaders to strike a balance between control, cost, and customization, like a balance that’s especially valuable as generative AI transitions from experimentation to production.
A 2024 Gartner survey found that over 68% of enterprises fine-tuning existing models reported up to a 3x improvement in task accuracy, with some achieving deployment cost reductions of nearly 40% compared to full-scale custom builds. Similarly, McKinsey research highlights that organizations leveraging domain-specific fine-tuning were two times more likely to scale AI across multiple business functions successfully.
However, fine-tuning isn’t without its challenges. Maintaining data quality, avoiding catastrophic forgetting (where models lose prior knowledge), and ensuring ethical transparency remain major concerns. In regulated industries such as finance and healthcare, the compliance implications of even small model shifts can be substantial.
As Aditya Pranav, VP- Engineering at Antino, explains:
“Fine-tuning is where AI stops being impressive and starts being useful. It’s not about creating intelligence, it’s about aligning intelligence with intent.”
This distinction captures why fine-tuning has become the most common and sustainable approach for enterprises advancing their AI strategies. Rather than reinventing the wheel, businesses can embed competitive differentiation directly into existing intelligence, creating a model that understands not just data, but context and objectives.
The result is an AI system that feels less like an external tool and more like a strategic partner, one that speaks your organization’s language, reflects your priorities, and scales your impact intelligently.
.png)
In the evolving landscape of enterprise AI, Retrieval-Augmented Generation (RAG) has emerged as a powerful middle ground, like a bridge between pre-trained intelligence and real-time business knowledge. It’s the hybrid model that combines the generative power of large language models (LLMs) with the precision and freshness of external data retrieval, redefining how organizations access, interpret, and act on information.
At its essence, RAG works by enhancing a model’s responses with up-to-date, organization-specific information drawn from internal databases, APIs, or external repositories. Instead of relying solely on what a model was trained on months (or years) ago, RAG dynamically fetches relevant context at query time, ensuring that every output is both accurate and contextually grounded.
This architecture effectively eliminates one of the biggest limitations of traditional AI models: the knowledge cutoff problem. For C-suite leaders, that translates into real-time intelligence for enabling decisions powered by data that evolves as quickly as the business does.
As enterprises generate unprecedented volumes of data, agility in information retrieval has become a competitive differentiator. According to IDC, enterprises now create and manage over 65% of the world’s data, with that figure expected to grow by 180 zettabytes by 2025. Yet, most organizations still report that employees spend up to 30% of their time searching for information across disconnected systems.
RAG directly addresses this fragmentation. By connecting generative AI models with enterprise data lakes, document management systems, and APIs, it enables answers, not searches, that are contextual, explainable, and instantly actionable.
A recent Deloitte survey revealed that over 55% of enterprises piloting generative AI are now prioritizing RAG implementations, citing its balance of accuracy, adaptability, and cost efficiency. Moreover, organizations integrating RAG architectures have reported up to 40% faster decision-making and 25% higher employee productivity, driven by improved access to real-time, contextual insights.
As Radhakanth Kodukula, Co-founder & CTO at Antino, observes:
“RAG is about amplifying human expertise. It ensures your AI doesn’t just recall what it once learned, but knows what’s happening right now.”
This hybrid paradigm has profound implications for business strategy. With RAG, enterprises can build AI systems that learn continuously, remain compliant effortlessly, and evolve dynamically alongside their data ecosystems. It represents a shift from static intelligence to living intelligence, one that grows and adapts with every query, every decision, and every customer interaction.
For leaders shaping their AI roadmap, RAG isn’t merely another option on the table. It’s the strategic catalyst that enables organizations to combine the best of both worlds, the scalability of pre-trained models and the precision of real-time data, unlocking a new era of responsive, context-aware intelligence.
What does this mean for businesses?
The strategic choice between Pre-Training, Fine-Tuning, and RAG depends less on technology and more on organizational maturity, data readiness, and business goals.
For the modern enterprise, the future is about building a composable AI ecosystem that blends them. Pre-trained models form the foundation, fine-tuning brings alignment, and RAG ensures agility.
Together, they enable businesses to move beyond experimentation to operational AI, one that learns faster, adapts continuously, and delivers measurable business outcomes.

While Pre-Training, Fine-Tuning, and RAG each have distinct purposes, the real competitive advantage for enterprises lies in orchestrating them together and not choosing one over the other. Leading organizations are now adopting layered AI strategies, where each stage builds upon the previous to balance capability, cost, and control.
This hybrid approach reflects a growing realization that AI maturity is architectural.
Enterprises that combine foundational intelligence with domain expertise and dynamic retrieval are the ones turning AI from a tool into a strategic infrastructure asset.
Enterprises begin by leveraging state-of-the-art, pre-trained foundation models developed by global leaders. These models serve as the core cognitive layer, providing language understanding, reasoning, and problem-solving capabilities that would otherwise take years to replicate internally.
Instead of reinventing the base model, businesses integrate it as a shared intelligence backbone, enabling every department to tap into a consistent AI foundation.
Next comes domain alignment. Through fine-tuning, organizations train the foundation model using proprietary, high-value datasets, such as customer interactions, financial histories, or compliance documents. This stage helps the model absorb industry-specific knowledge and organizational tone, transforming general intelligence into contextual competence.
Many enterprises now adopt a modular fine-tuning strategy, maintaining separate tuned instances for different functions (e.g., HR, finance, customer support), all built upon the same pre-trained core. This ensures consistency at the center with flexibility at the edges.
Once the model is trained and aligned, RAG (Retrieval-Augmented Generation) ensures it never becomes outdated. By integrating internal databases, APIs, and external knowledge sources, RAG enables real-time data retrieval that keeps responses current, explainable, and traceable.
This is where enterprise AI transitions from being reactive to responsive. Instead of retraining models every few months, RAG allows AI systems to evolve daily, mirroring the pace of business change.
Together, these three components form what many leading enterprises now call a “living AI stack.”
For instance, a global bank might use a pre-trained LLM as its foundation, fine-tune it on proprietary financial data for compliance and accuracy, and then deploy RAG to pull in live market data and regulatory updates in real time. The result would be an AI advisor that not only understands banking but adapts daily to new market dynamics.
According to a 2025 Accenture report, enterprises using this 3-tiered AI architecture have achieved:
For C-suite leaders, this integrated approach offers the best of all worlds:
Antino, being a leading AI development company, recognizes that no two AI journeys look alike, because no two businesses do. Our approach begins not with the technology, but with your business objectives. We work closely with enterprises to assess their data maturity, operational goals, and regulatory environment before defining the most effective AI strategy, whether that means training proprietary models, fine-tuning existing architectures, or implementing RAG-based systems for dynamic intelligence.
By combining deep technical expertise with a product mindset, we help organizations build AI ecosystems that are foundational to long-term digital growth.
Our team brings together expertise across AI/ML engineering, enterprise mobility, and intelligence solutions, enabling seamless integration of data-driven capabilities into your existing workflows. From designing scalable model pipelines to optimizing performance and compliance, we ensure your AI strategy delivers measurable business impact and not just theoretical promise.
With Antino, you evolve with AI, step by step, guided by insights, grounded in strategy, and powered by innovation. So, contact us right away!









%20(1).png)

-min-min.png)