.png)
The cost your CFO sees and the cost your CFO does not! This article is worth your time!
Your CFO sees the invoice. Rack space. Cooling infrastructure. Software licenses. Network bandwidth. The quarterly HPC bill lands on the desk, gets reviewed against the budget, and moves on.
But here is the question that rarely makes it into that review: How much of that infrastructure investment is actually working for you?
According to a 2024 report by IDC, enterprises globally spent over $53 billion on HPC infrastructure. Yet studies consistently show that average HPC cluster utilization in enterprise environments sits between 40% and 60%. You are, in many cases, paying for a high-performance machine and running it at half speed, or worse, running it fast on the wrong workloads entirely.
That is not an infrastructure problem. That is a leadership problem.
The Gartner HPC Hype Cycle for 2024 flagged workload inefficiency and suboptimal resource scheduling as the top two contributors to enterprise HPC underperformance.

McKinsey's technology research arm found that organizations with mature HPC optimization strategies saw up to 35% improvement in time-to-insight for data-intensive operations, which in industries like pharmaceuticals, financial services, and advanced manufacturing can mean months of competitive advantage.
Consider this: if your organization spends $10 million annually on HPC infrastructure and your effective utilization is 50%, you are operating with $5 million of productive compute. That gap does not show up as a line item. It shows up as delayed drug trials, late risk model recalibrations, slow product simulations, and engineering bottlenecks that compound over quarters.
So the real question for the leadership table is not "What are we spending on HPC?" but "What is our HPC spending actually producing?"
This blog is for organizations that are ready to move from the first question to the second.
When most technology leaders hear "HPC optimization," they think of hardware upgrades. Faster processors. More memories. Better interconnects. While those investments can matter, they represent only one dimension of a far more complex equation.
HPC optimization for enterprises is the systematic process of aligning computational resources, workload design, software configuration, and organizational processes to extract maximum value from high-performance computing environments. It operates across several distinct but interdependent layers.
At the infrastructure layer, HPC system optimization involves tuning compute nodes, memory hierarchies, storage subsystems, and network fabric for peak throughput. But this is table stakes. Every enterprise with a serious HPC investment has done some version of this.
.png)
HPC workflow optimization addresses how computational jobs are structured, sequenced, prioritized, and scheduled. Two organizations with identical hardware can produce dramatically different results depending on how intelligently their workloads are managed. A poorly designed workflow can cause jobs to queue unnecessarily, create I/O bottlenecks, or consume memory in ways that block parallel processing.
HPC application optimization looks at the code itself: whether algorithms are parallelized effectively, whether applications are leveraging available accelerators like GPUs, whether memory access patterns are efficient, and whether the software stack is aligned with the underlying hardware architecture.
Strategic optimization, which receives the least attention despite having the highest leverage: Are you running the right workloads on HPC at all? Are you matching problem types to the right compute paradigms? Is your HPC environment integrated with your data pipeline in a way that eliminates bottlenecks upstream and downstream?
Enterprises that treat HPC optimization as purely a technical exercise tend to optimize the wrong things. They tune systems that are running the wrong workloads. They accelerate processes that are poorly designed. They invest in infrastructure for problems that could be solved differently.
The organizations pulling ahead are the ones where HPC performance optimization is a strategic conversation, not just a systems administration task.
The uncomfortable reality is that most enterprise HPC environments were not built for what they are being asked to do today. They were designed in an era where workloads were relatively predictable, datasets were smaller, and the pace of computational demand was slower.
That world no longer exists.
Ask yourself this: When was the last time your HPC environment was comprehensively reviewed for strategic alignment rather than just operational stability?
If the answer is "more than 18 months ago," you are likely operating with significant hidden inefficiency.
There are 5 structural reasons why enterprise HPC environments underperform.
As business units discover the power of computational modeling, simulation, and large-scale analytics, they begin submitting workloads to HPC environments without standardized frameworks. The result is a congested queue where a low-priority research job competes with a time-critical production simulation. Absence of workload governance is one of the most common contributors to HPC performance degradation.
Many enterprise HPC environments have upgraded hardware multiple times while keeping legacy application layers largely intact. The result is modern processors running decades-old code that was never designed for current processor architectures, memory hierarchies, or parallelization paradigms. According to the Lustre file system consortium's 2023 benchmarking study, application-to-hardware mismatch is responsible for performance gaps of 20% to 45% in otherwise well-configured HPC clusters.
HPC environments that lack granular telemetry cannot self-correct. Jobs that fail silently waste computing hours. Bottlenecks that develop gradually go undetected until they cause a major disruption. Without continuous performance visibility, optimization is reactive at best.
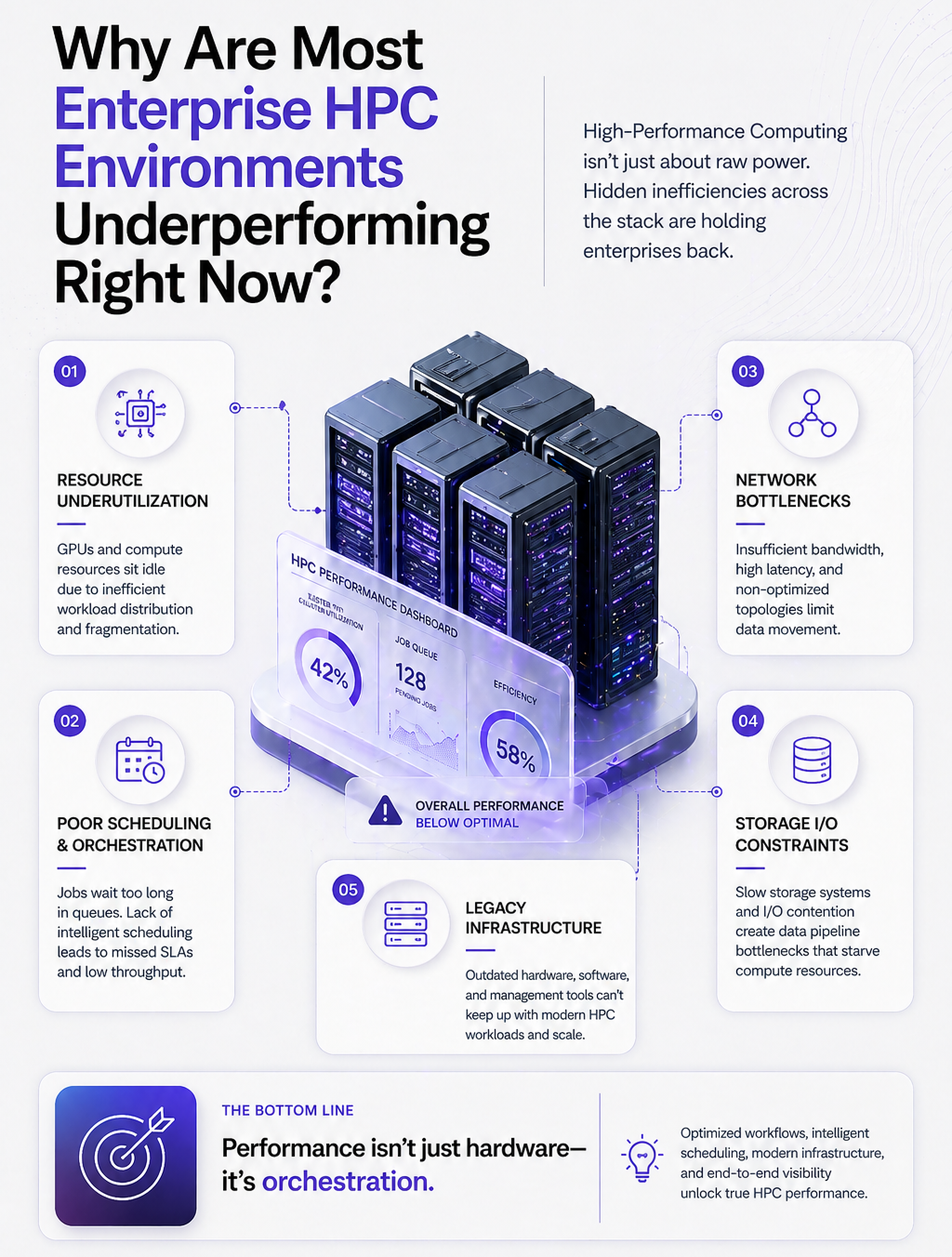
Most enterprises have adopted some form of hybrid compute strategy, but few have integrated their on-premises HPC infrastructure with cloud compute in a genuinely orchestrated way. The result is manual workload migration, inconsistent performance, and missed opportunities for burst computing during peak demand periods.
HPC teams are typically excellent at systems management. They are rarely empowered or positioned to translate HPC capability into business outcome language. This creates a persistent gap between what is technically possible and what is actually being leveraged.
"The organizations that win with technology are not the ones with the best technology. They are the ones that best align technology with what they are trying to accomplish as a business." Satya Nadella, CEO, Microsoft
That alignment gap is where most enterprise HPC value is being lost today.
For the C-suite, the case for HPC performance optimization cannot live in technical documentation. It needs to translate directly to the metrics that govern enterprise decision-making: time to market, risk exposure, cost per output, and competitive positioning.
Let us make that translation explicit.
In financial services, quantitative risk modeling, Monte Carlo simulations, and real-time fraud detection all run on HPC infrastructure. A 2023 analysis by Accenture found that financial institutions with optimized HPC workflows reduced model recalibration cycles by an average of 28%, enabling faster response to market volatility. In an environment where pricing accuracy and risk response speed are measurable competitive advantages, that improvement is not incremental. It is structural.
In pharmaceutical and life sciences, the stakes are even higher. Drug discovery pipelines depend heavily on molecular dynamics simulations and genomic data processing. Optimized HPC workflows at Moderna enabled the organization to compress certain computational research phases from weeks to days during their mRNA platform development. While the specific infrastructure details vary, the pattern is consistent: organizations that have invested in HPC workflow optimization are completing research cycles faster and with greater fidelity.
.png)
In advanced manufacturing and aerospace, digital twin environments, computational fluid dynamics, and finite element analysis are now core to product development. Boeing's engineering teams have publicly discussed how HPC optimization initiatives enabled them to run more simulation iterations per development cycle, reducing physical prototype dependency and accelerating design validation timelines.
In energy and natural resources, seismic processing and reservoir modeling are computationally intensive operations where optimization directly affects exploration accuracy and capital allocation decisions. Companies in this space that have modernized their HPC application optimization frameworks have reported processing time reductions of 30% to 50% for equivalent seismic datasets.
The pattern across industries is consistent. HPC optimization for enterprises is not a technology investment. It is a time compression and decision quality investment. It enables organizations to run more scenarios, test more hypotheses, respond to more market signals, and deliver better outputs per unit of compute spend.
The question for your leadership team is not whether HPC optimization creates value. The question is whether you are capturing that value or leaving it on the table.
One of the most consequential decisions in enterprise HPC strategy is the deployment model. And it is a decision that too many organizations make based on either inertia or cost modeling alone, without accounting for the workload characteristics that actually determine performance.
There is no universal answer. But there is a structured way to think about it.
On-premises HPC remains the right choice for workloads that are highly predictable in volume, require sustained high-throughput processing, involve sensitive data with strict sovereignty requirements, or demand extremely low-latency interconnects. Manufacturing simulation environments, regulated financial modeling, and classified research computing typically fall into this category. HPC system optimization in on-premises environments centers on hardware tuning, scheduler configuration, storage I/O optimization, and network fabric management.
The risk with on-premises is overcapitalization. Organizations that dimension their HPC infrastructure for peak demand pay for capacity that sits idle the majority of the time. This is where utilization-based cost accounting becomes critical for leadership conversations.
Cloud-based HPC has matured significantly. AWS ParallelCluster, Microsoft Azure HPC, and Google Cloud's HPC offerings provide enterprise-grade compute configurations with GPU acceleration, high-speed interconnects, and sophisticated workload management. Cloud HPC is particularly well-suited for burst workloads, variable-demand research computing, and organizations that need to access specialized hardware (like A100 or H100 GPUs) without committing to capital expenditure.
The risk with pure cloud HPC is performance consistency and egress costs. For sustained, high-volume workloads, cloud HPC can become expensive in ways that are not fully visible until bills arrive. HPC application optimization becomes especially important in cloud environments, because inefficient code translates directly into higher per-job costs.
Hybrid HPC is where most sophisticated enterprise strategies are landing in 2026. The principle is straightforward: run baseline, predictable workloads on owned or leased on-premises infrastructure, and burst to the cloud for demand spikes, specialized hardware needs, or geographic distribution requirements. The complexity is in the orchestration. A hybrid HPC strategy that lacks intelligent workload routing, unified monitoring, and consistent scheduling frameworks will underperform both alternatives.
"The future of enterprise computing is not a choice between on-premises and cloud. It is the intelligent orchestration of both, governed by workload characteristics rather than procurement preferences." Werner Vogels, CTO, Amazon Web Services
For C-suite leaders, the hybrid model requires cross-functional alignment that goes beyond the IT function. Finance needs to understand the cost variability model. Operations needs visibility into workload prioritization logic. Risk needs clarity on data handling across environments. This is why the HPC optimization strategy is fundamentally a leadership conversation.
The right question is not "which deployment model do we choose?" but "which workloads belong where, and how do we make that routing intelligent and automated?"
The gap between HPC leaders and HPC laggards is widening. Organizations that have treated HPC optimization as a strategic priority are pulling ahead in ways that are becoming difficult to catch up to.
Here is what the leaders are doing differently.
The most effective HPC environments in 2026 are not managed solely by IT. They are governed by a cross-functional council that includes representatives from business units, finance, risk, and technology. Workload prioritization decisions are made against business value frameworks, not just technical parameters. This shift ensures that HPC resources flow toward the highest-value problems rather than the loudest requesters.
Traditional HPC job schedulers like SLURM and PBS operate on rule-based frameworks. Leading organizations are now layering machine learning on top of these systems to predict job completion times, dynamically reallocate resources, and reduce queue wait times. Early adopters of AI-assisted HPC scheduling are reporting 15% to 25% improvements in effective throughput without any additional hardware investment.
In most enterprises, HPC performance reviews happen quarterly or in response to incidents. Leaders have established continuous monitoring frameworks with automated alerting, anomaly detection, and performance benchmarking that run in the background at all times. Problems are identified and addressed before they compound.
Code-level optimization is unglamorous but enormously impactful. Organizations that have conducted systematic application profiling, eliminated memory leaks, improved parallelization, and ported applications to GPU-accelerated frameworks have seen performance improvements measured in multiples, not percentages, for specific workload classes.
HPC performance is often limited not by compute but by data movement. Leaders have invested in high-performance storage architectures, data staging strategies, and pipeline automation that ensure data arrives at the compute layer in the format and at the speed that HPC applications require.
"Every business will need to become a data business. But data without the computer infrastructure to process it at speed is just expensive storage." Lisa Su, CEO, AMD
The most mature HPC organizations assign product managers to their HPC environments. These individuals understand both the technical constraints and the business requirements, and they manage HPC as a platform with defined SLAs, roadmaps, and stakeholder communication cadences. This brings business rigor to what has traditionally been a purely technical function.
The defining characteristic of HPC leaders in 2026 is not the hardware they have bought. It is the organizational discipline they have built around extracting value from it.
Acknowledging the need for HPC optimization is easier than executing it. Organizations face a set of recurring challenges that, left unaddressed, cause optimization initiatives to stall or deliver fragmented results.
You cannot optimize what you cannot measure. Many enterprise HPC environments lack the telemetry infrastructure to understand where time and resources are actually being consumed. Without granular performance data at the job, node, and application level, optimization decisions are made on assumptions rather than evidence.
The response is to establish a comprehensive monitoring foundation before any optimization work begins. This means deploying performance profiling tools across the HPC stack, establishing baseline benchmarks for key workload classes, and creating dashboards that give both technical teams and business stakeholders visibility into HPC performance and utilization.
Business units that have become accustomed to submitting workloads on demand often resist governance frameworks that introduce prioritization or scheduling constraints. This resistance is understandable but strategically damaging.
The most effective approach is to make the value of governance visible. When teams can see that workload prioritization is delivering faster turnaround for business-critical jobs, and that governance is a mechanism for improving their outcomes rather than restricting their access, adoption follows. Leadership sponsorship is essential here. Governance frameworks that do not have C-suite backing rarely survive contact with a frustrated business unit head.
Many enterprise HPC applications have accumulated years of technical debt. They were written for hardware architectures that no longer exist, never parallelized effectively, and have not been profiled or refactored in years. This is a significant optimization barrier because infrastructure improvements cannot compensate for application inefficiency.
Addressing application-level technical debt requires honest assessment and prioritization. Not every application warrants a ground-up rewrite. The starting point is identifying the applications that consume the most compute resources or sit on the longest critical paths and investing optimization effort proportional to their business impact.
.png)
Effective HPC performance optimization requires a rare combination of skills: deep knowledge of computer architecture, parallel programming expertise, domain-specific understanding of the workloads involved, and the ability to translate technical findings into business recommendations. These skills do not exist in abundance.
Organizations addressing this challenge are using a combination of targeted hiring, partner-led engagements, and internal capability building. Bringing in specialized expertise for the diagnostic and design phases while investing in building internal HPC engineering capability for ongoing management is a pattern that delivers both immediate impact and long-term sustainability.
As enterprises adopt hybrid compute strategies, the complexity of HPC management increases substantially. Job scheduling across heterogeneous environments, data movement between on-premises and cloud storage, and consistent security posture across boundaries are all non-trivial problems.
The organizations managing this most effectively have invested in unified orchestration platforms that provide a single control plane across their HPC environments, regardless of where the computer physically resides. Solutions like IBM Spectrum LSF, Altair PBS Professional, and cloud-native HPC management tools are increasingly capable of managing this complexity, but they require deliberate configuration and integration work to deliver their potential.
"Complexity is the enemy of execution. In HPC as in strategy, the organizations that simplify without sacrificing capability are the ones that win."Ginni Rometty, former CEO, IBM
This is the point where many organizations get stuck. HPC optimization gets handed to the technology team, a report gets produced, some recommendations get implemented, and eighteen months later, the enterprise is back in the same position: underutilizing expensive infrastructure while the competitive gap widens.
That cycle persists because HPC optimization is being treated as a technical initiative rather than a strategic one.
Consider what effective HPC optimization actually requires. It requires business leaders to articulate which workloads are most strategically valuable and deserve priority access to compute resources. It requires finance to establish cost accounting frameworks that make HPC utilization visible and create the right incentives. It requires operations to align HPC delivery timelines with business planning cycles. It requires risk and compliance to define the governance boundaries within which HPC environments must operate. And it requires technology to translate all of those inputs into a system that performs reliably and efficiently.
None of those inputs can come from the technology team alone.
The most important shift in perspective for C-suite leaders is this: HPC optimization is not a cost reduction exercise. It is a competitive capability investment.
When Boeing reduces design validation time through HPC workflow optimization, that is a competitive advantage in aerospace. When a pharmaceutical company compresses computational drug discovery cycles through HPC application optimization, that is a competitive advantage in therapeutics. When a financial institution improves the speed and accuracy of its risk models through HPC system optimization, that is a competitive advantage in capital markets.
The question is not whether your organization can afford to invest in HPC optimization. The question is whether your organization can afford not to, while competitors who have made that investment continue to accelerate.
What is the cost of one delayed product launch to your enterprise?
What is the value of one additional simulation cycle per development sprint?
What would 20% faster risk model recalibration mean for your trading operation?
Those are the calculations that belong on the leadership agenda alongside the infrastructure invoice.
Antino has built its HPC practice on a straightforward premise that technical excellence without business alignment is waste in motion. The organizations that extract the most value from HPC investments are the ones that have made optimization a strategic discipline, not just a technical one.
Antino works with enterprise clients across the full spectrum of HPC optimization. This includes HPC environment assessments that establish honest performance baselines against industry benchmarks, workload analysis that identifies the highest-value optimization opportunities within your specific operating context, and architecture design for hybrid HPC strategies that align deployment models with workload characteristics rather than procurement convenience.
If your HPC environment is consuming a significant budget but you lack clarity on whether it is delivering proportionate business value, that is the conversation Antino is built to have. If you are planning a significant HPC investment and want to ensure the architecture decisions you make today will serve your organization five years from now, that is a conversation Antino is built to lead.
To explore how HPC optimization can drive measurable business outcomes for your organization, connect with the Antino team.




















